


在 AI Agent 时代,网页抓取的痛点不再是“怎么抓”,而是“Token 太贵”。OpenClaw Zero Token 是一个旨在通过优化 Context(上下文)和接入低成本/免费模型接口,实现高效率、低消耗甚至零 Token 消耗的自动化框架。
本教程将手把手带你完成从环境搭建到第一个自动化任务的运行。
一、 环境准备
在开始之前,请确保你的电脑已安装 Python 3.10+ 以及 Git。
1. 克隆项目与安装依赖
打开终端(或 CMD),执行以下命令:
Bash
# 克隆仓库
git clone https://github.com/linuxhsj/openclaw-zero-token.git
cd openclaw-zero-token
# 创建并激活虚拟环境 (推荐)
python -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# 安装核心依赖
pip install -r requirements.txt
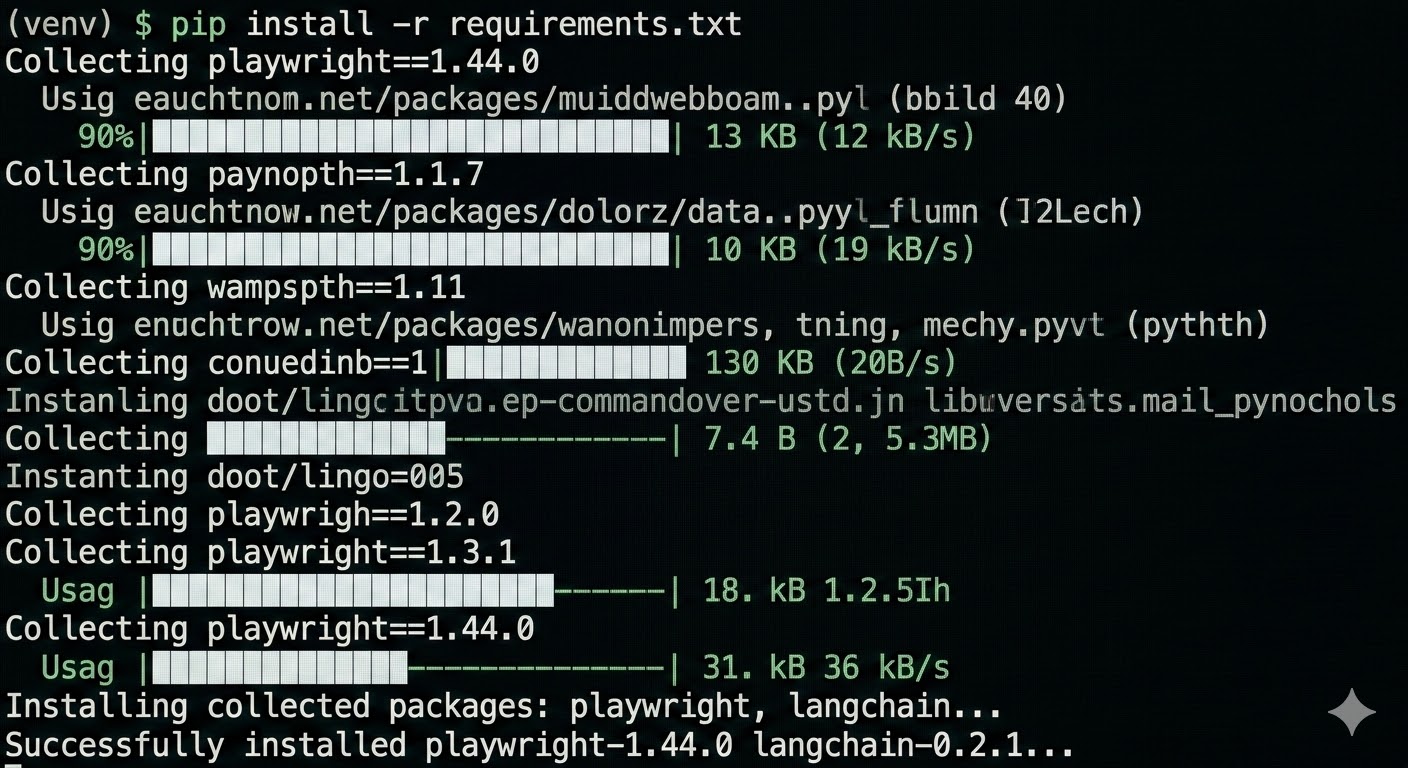
2. 初始化浏览器内核
OpenClaw 依赖 Playwright 来模拟真实浏览器行为,第一次使用需要安装驱动:
Bash
playwright install chromium
二、 核心配置:开启“零 Token”模式
该项目的强大之处在于它对底层模型(LLM)的灵活调度。
1. 配置文件设置
在项目根目录找到 .env.example,复制并重命名为 .env:
Bash
cp .env.example .env
2. 接入模型(白嫖方案)
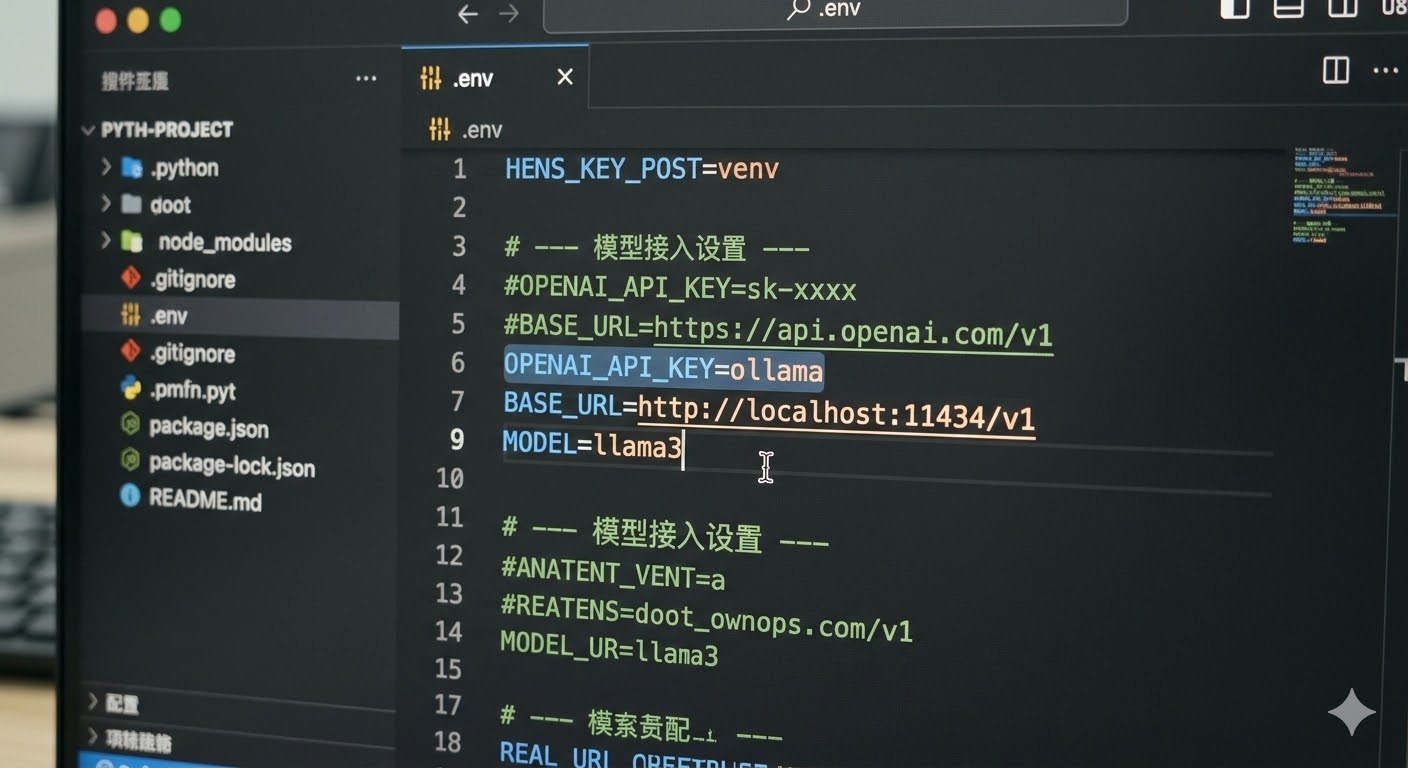
打开 .env 文件,你有两种实现“零成本”的选择:
方案 A(本地自建): 运行 Ollama,本地部署
Llama 3或Qwen 2。将BASE_URL指向http://localhost:11434/v1。方案 B(白嫖 API): 接入提供免费额度的平台(如 DeepSeek 早期赠送额度或硅基流动等聚合平台的免费模型)。
三、 实战演练:抓取你的第一个网页
项目内置了 example.py。我们可以编写一个简单的逻辑:让 AI 访问某个技术文档并提取关键点。
1. 编写任务脚本
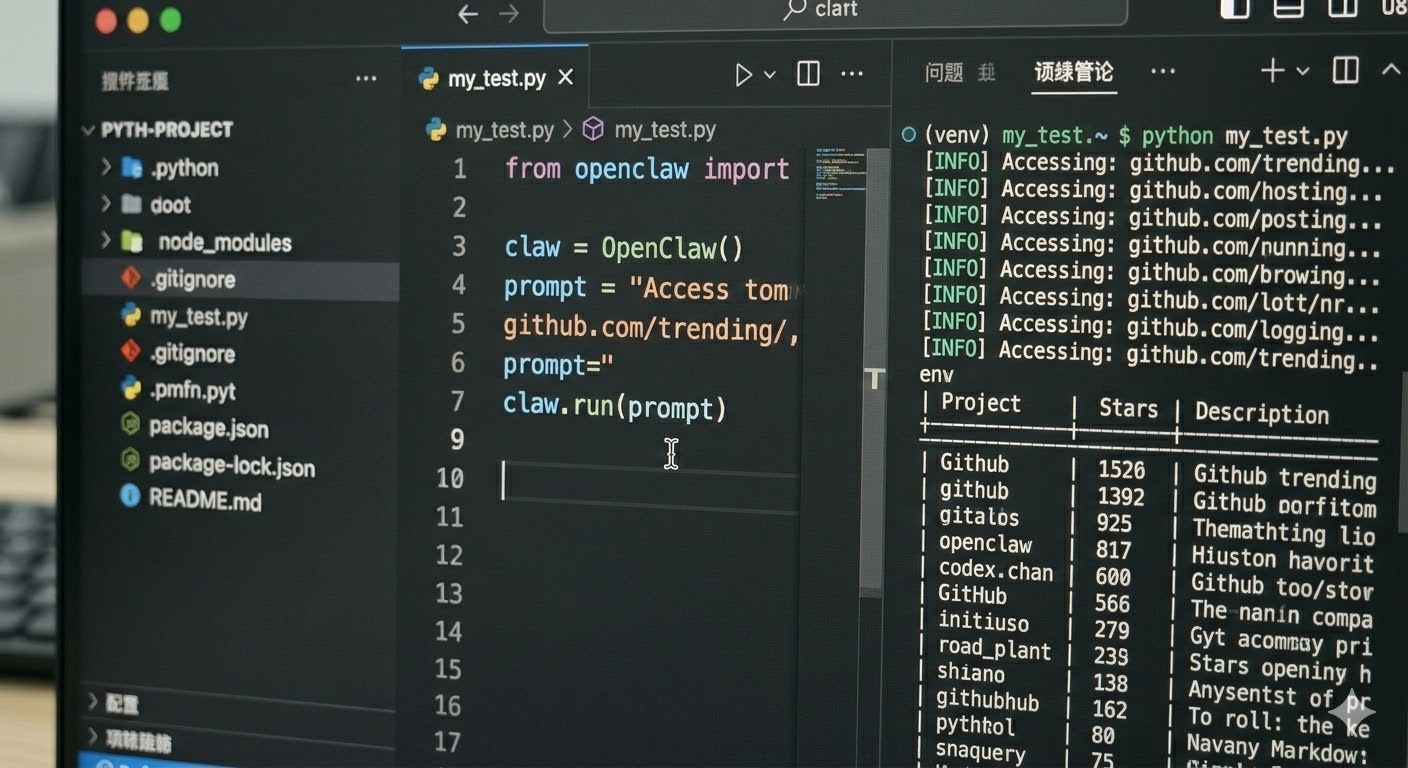
创建一个 my_test.py:
Python
from openclaw import OpenClaw
# 初始化抓取助手
# 如果你在 .env 配置好了,这里会自动读取
claw = OpenClaw()
# 定义你的需求(用自然语言描述)
prompt = """
访问 https://github.com/trending
提取当前排名 Top 5 的项目名称、Star 数以及项目简介。
请以 Markdown 表格形式输出。
"""
# 执行任务
print(">>> 正在启动 AI 自动化抓取...")
result = claw.run(prompt)
print("\n--- 抓取结果 ---")
print(result)
四、 深度解析:OpenClaw 是如何省钱的?
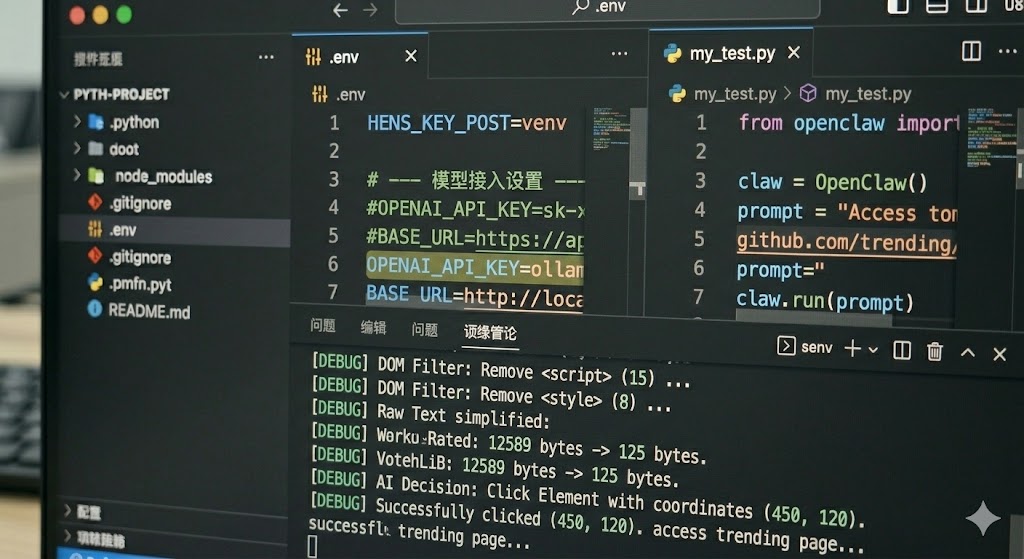
为什么它叫 Zero Token?主要归功于它的 “DOM 瘦身术”。
普通的 AI 抓取会将整个网页 HTML 喂给大模型,这会产生数万 Token 的消耗。OpenClaw 在发送给 AI 之前会进行以下操作:
标签过滤: 自动剔除
<script>、<style>、<svg>等与内容无关的标签。语义提取: 只保留关键的文本节点和交互元素(按钮、输入框)。
坐标映射: 将元素简化为 AI 易于理解的坐标,极大减少了 Prompt 的长度。
五、 常见问题与调试
遇到反爬: 可以在配置中开启
headless=False,观察浏览器是如何被拦截的,必要时更换 User-Agent。模型幻觉: 如果 AI 找不到按钮,尝试在 Prompt 中更具体地描述目标(例如:“点击那个蓝色的登录按钮”)。
六、 总结与展望
OpenClaw Zero Token 不仅仅是一个爬虫,它更像是一个拥有“眼睛”和“手”的本地机器人。通过降低 Token 门槛,它让个人开发者也能低成本构建复杂的自动化工作流。
项目 GitHub: linuxhsj/openclaw-zero-token
进阶方向: 尝试将其集成到你的每日新闻推送或竞品监控脚本中。


评论区