


在 2026 年的今天,AI 基础设施正处于一个十字路口。一边是如日中天的通用算力霸主 NVIDIA,另一边是主张“将模型刻入硅片”的激进挑战者 Taalas。这不仅是两家公司的竞争,更是两种底层哲学——软件定义硬件与硬件固化算法——的巅峰对决。
1. 架构对决:灵活性 vs 极致效率
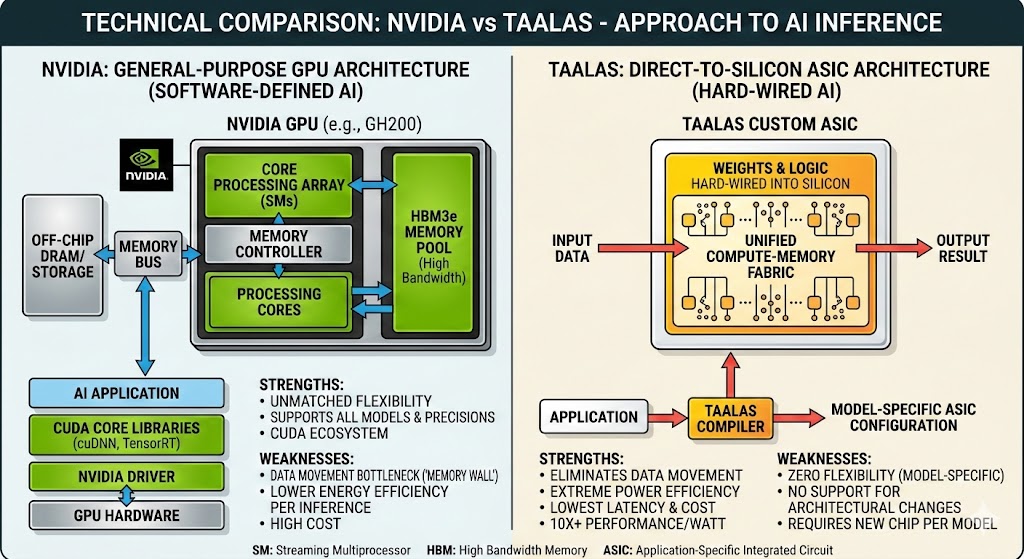
NVIDIA:万能的通用计算引擎
NVIDIA 的 GPU 本质上是一个极其强大的通用并行处理器。
技术核心:通过 CUDA 软件栈,它可以在同一块芯片上运行从 Llama 到 Stable Diffusion,再到复杂的物理仿真。
挑战(内存墙):GPU 的计算单元和存储单元(HBM)是分离的。为了运行 AI 模型,数据必须在显存和核心之间不断搬运,这导致了巨大的功耗和延迟。
Taalas:模型即硬件 (Model-as-Hardware)
Taalas 采取了截然相反的路径。他们不制造“能跑 AI 的芯片”,而是直接制造“Llama 3.1 8B 芯片”。
技术核心:Taalas 将模型的权重(Weights)直接固化在芯片的掩膜 ROM(Mask ROM)中。这意味着模型就在计算单元旁边,彻底消除了数据搬运。
创新点:他们开发了自动化的“Direct-to-Silicon”流程,能在 60 天内将一个软件模型转化为一颗专用的 ASIC 芯片。
2. 性能实测:10倍速的代价
以下是针对主流模型 Llama 3.1 8B 的性能对比估算:
3. 优势与劣势深度分析
NVIDIA:生态的护城河
优点:
无可比拟的适应性:当研究界发明了新的架构(如从 Transformer 转向混合专家模型 MoE),NVIDIA 只需要更新驱动。
CUDA 生态:开发者无需理解底层逻辑,直接调用 API。
缺点:
效率损耗:为了通用性,芯片上大量的晶体管浪费在了调度和缓存管理上。
供应链依赖:过度依赖 HBM 显存,导致价格高昂且供货紧张。
Taalas:推理的“印钞机”
优点:
瞬时响应:推理延迟低于 1 毫秒,AI 交互从“流式输出”变成了“瞬间呈现”。
极致简化:抛弃了昂贵的 HBM、液冷系统和复杂的 I/O,极大地降低了数据中心的运营难度。
缺点:
“过时”风险:如果 Meta 发布了 Llama 4,而你刚买了一万颗 Llama 3 专用芯片,这些芯片瞬间变成废铁。
规模限制:目前仅适用于 8B-20B 左右的中小型模型,超大规模模型(如 GPT-4 级别)仍需依赖集群。
4. 行业启示:AI 硬件的分层时代
未来,我们可能会看到 AI 算力市场的两极分化:
训练与尖端科研(NVIDIA 的领地):对于需要不断尝试新算法、大规模训练模型的场景,NVIDIA 的通用性是不可替代的。
高频、稳定的推理服务(Taalas 的机会):对于已经固化的、需要海量部署的模型(如手机端的语音助手、翻译、特定业务的分类器),Taalas 式的专用芯片将提供几十倍的降本增效。
结语:
如果说 NVIDIA 是能做满汉全席的顶级厨房,Taalas 就是那台只做招牌牛肉面且每秒出一碗的自动售卖机。在追求极致性价比的下半场,谁能笑到最后,取决于 AI 模型架构何时趋于稳定。


评论区